Super Individual Program
“超级个体” 培养计划
第一期 全栈开发能力培养
培训人
诗雅 + 陈明
cd 你的项目目录
codex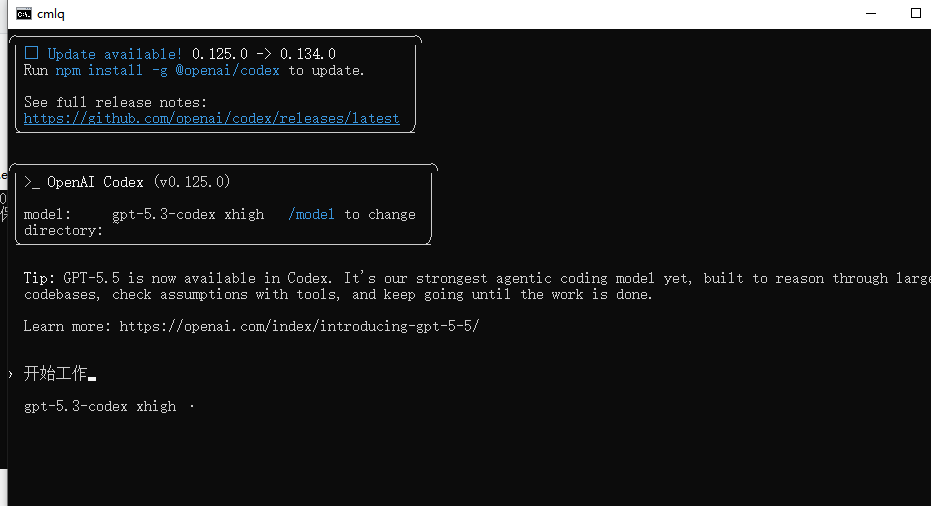
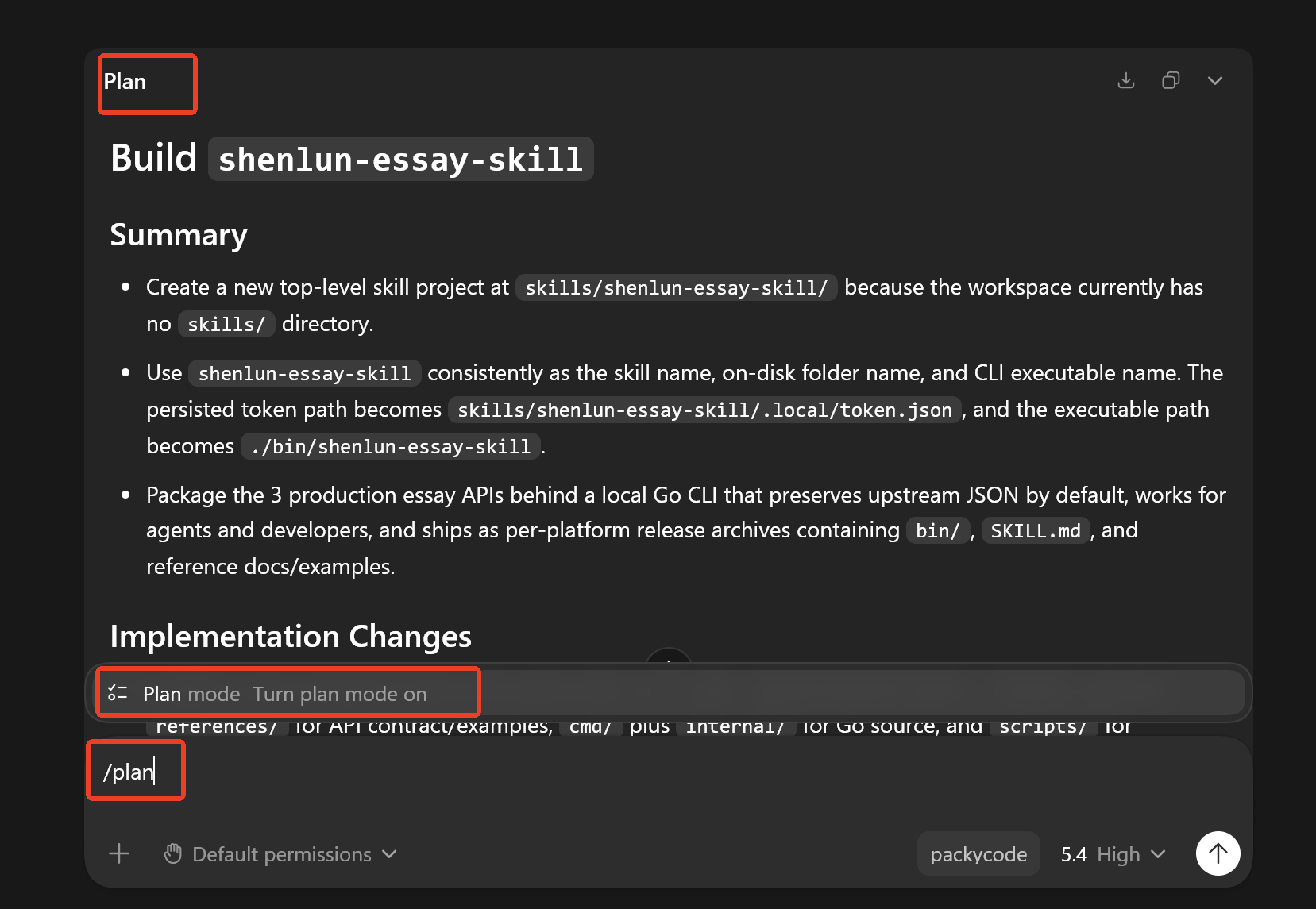
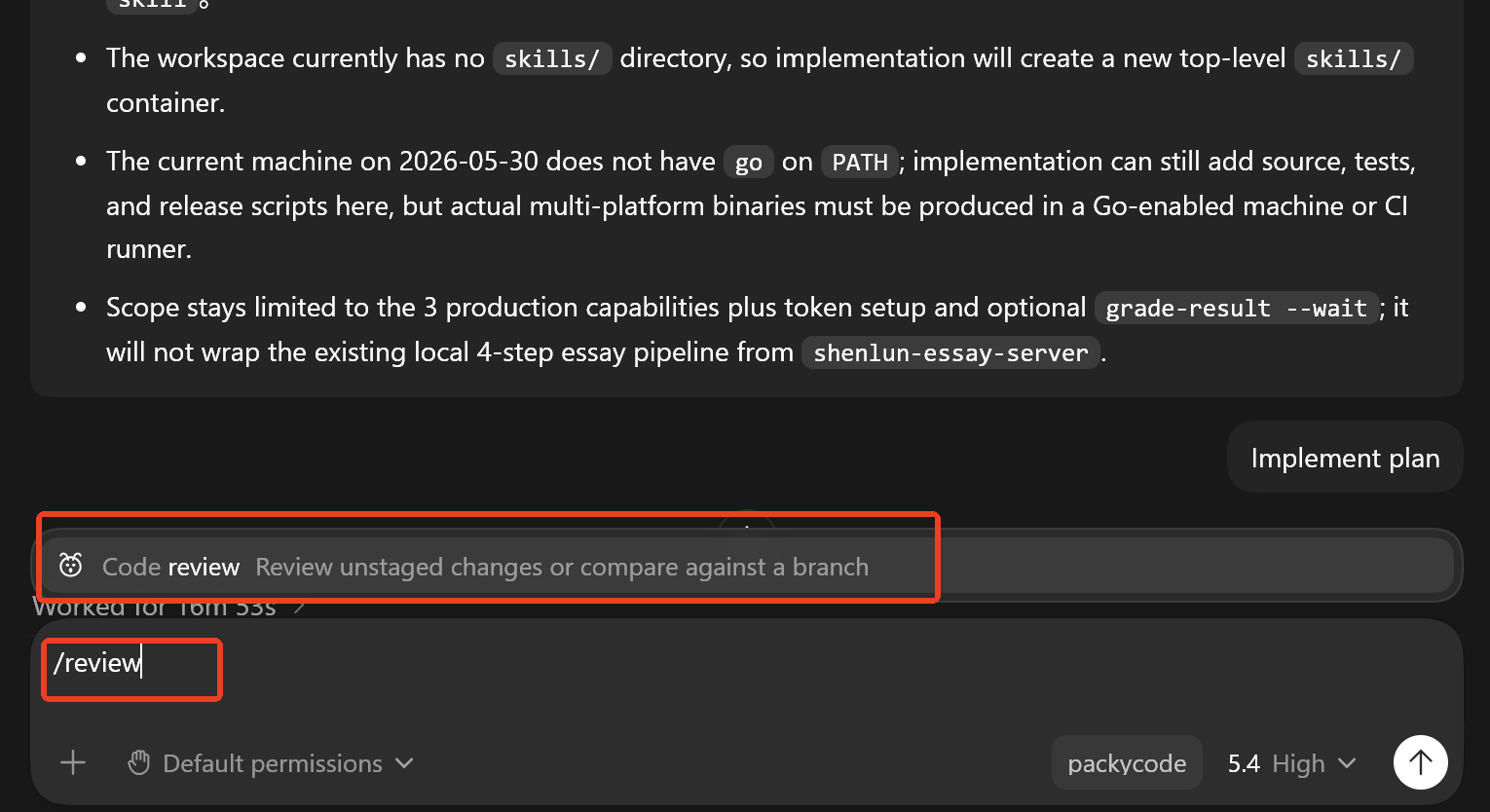
为什么要先选工作区:工作区决定 Agent 能看到哪些代码、文档和配置,也决定后续修改会落在哪个项目里。任务做对但改错目录,等于没有完成交付。
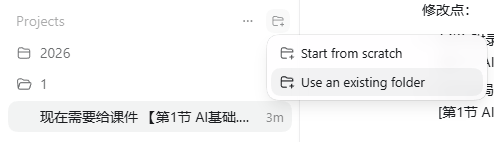
cd 进入目标项目根目录,再运行 codex。cd 你的项目目录
codex